Step into MoE
专家混合(Mixture of Experts)是一种人工智能技术,其中一组专门的模型( 专家 )由门控机制编排,以处理输入的不同部分。这种“分而治之”的策略优化了性能和效率。它利用了这样一个事实,即专门针对特定领域的较弱模型的集合可以产生更准确的结果,类似于传统的机器学习集合。但是,它在生成过程中引入了输入的动态路由。
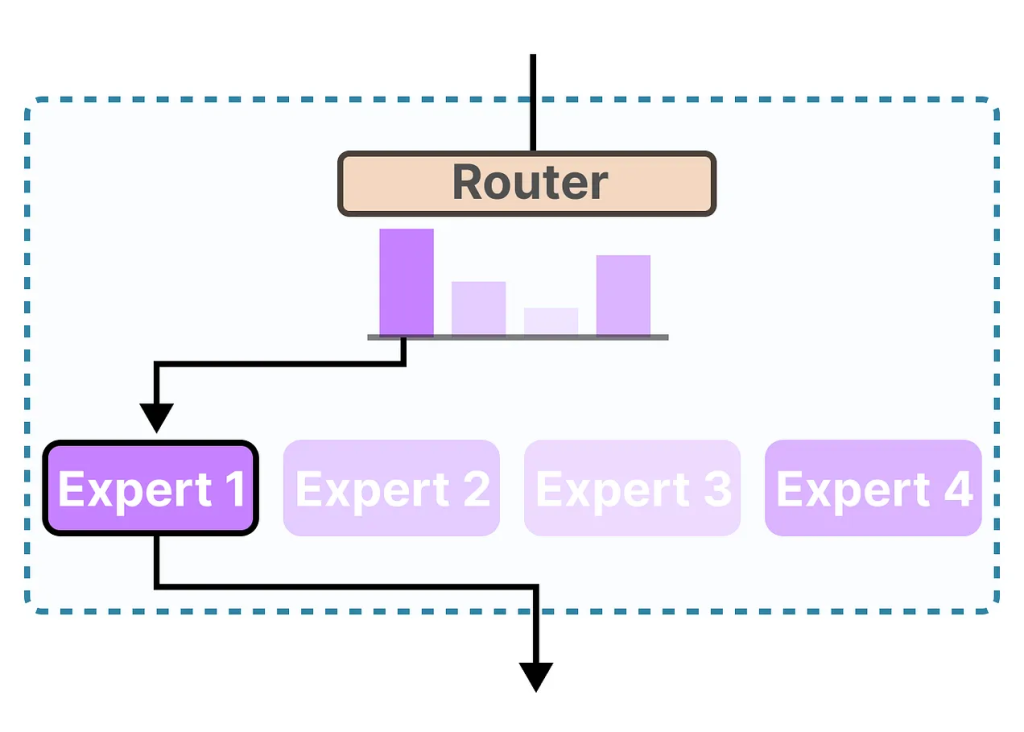
MoE 的结构主要由两个核心组成部分构成:
- 专家(Experts) :每一层前馈神经网络(FFNN)不再是一个单一结构,而是由多个“专家”组成。每个“专家”本质上也是一个前馈神经网络。
- 路由器(Router)或门控网络(Gate Network) :负责决定每个 token(词元)应该被送到哪些专家那里去处理。
在使用 MoE 架构的大语言模型中,我们会在模型的每一层看到多个(具有一定专长的)专家:
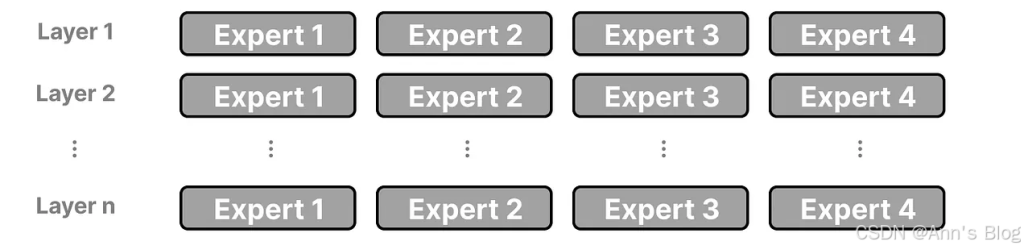
需要注意的是,这里的“专家”并不是指在某个具体学科领域(比如“心理学”或“生物学”)特别擅长的模型。它们最多只是在处理某些词语的语法结构方面表现更好:

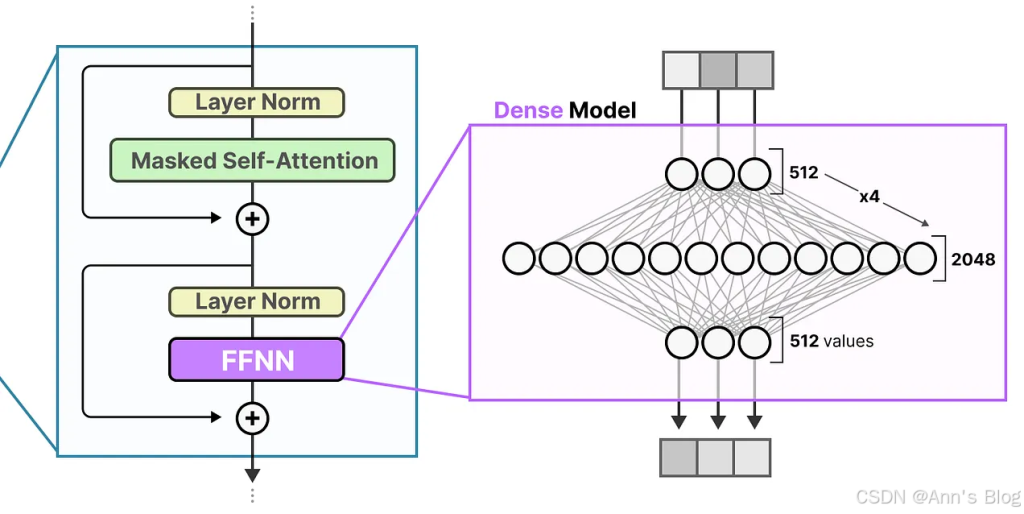
专家混合模型(MoE)的出发点,是 LLM 中最基础的组件之一:前馈神经网络(FFNN, Feedforward Neural Network) 。
回想一下,在一个标准的仅解码器(decoder-only)Transformer 架构中,FFNN 放是在层归一化(layer normalization)之后的:
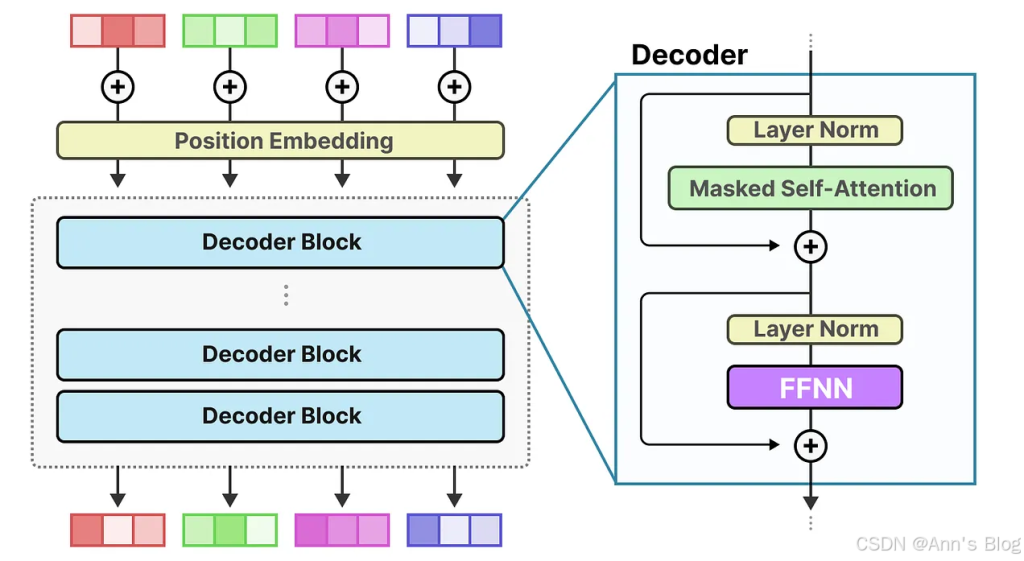
不了解decoer-only Transformer的人看到上面这个图可能会困惑。下面讲解一下:
input
│
├─ Masked Multi-Head Self-Attention
├─ Residual Add + LayerNorm
│
├─ Encoder-Decoder Cross Attention
├─ Residual Add + LayerNorm
│
├─ Feedforward Neural Network (FFNN)
├─ Residual Add + LayerNorm
这是正常的post-ln Transformer
但是decoder-only Transformer架构的模型,比如gpt系列,用的pre-ln,并且因为是decoer-only,所以不需要交叉注意力层(或者叫编码器解码器注意力层),因此构架是这样的:
Input
│
├─ LayerNorm
│
├─ Masked Multi-Head Attention
│
├─ Residual Add
│
├─ LayerNorm
│
├─ Feedforward Neural Network (FFNN)
│
├─ Residual AddFFNN 的作用,是利用注意力机制生成的上下文信息,并进一步转换这些信息,从而捕捉数据中更复杂的关联关系。
不过,FFNN 的规模增长得非常快。为了学到这些复杂关系,它通常会对输入数据进行“扩展”:
Contents
Sparse Layers稀疏层
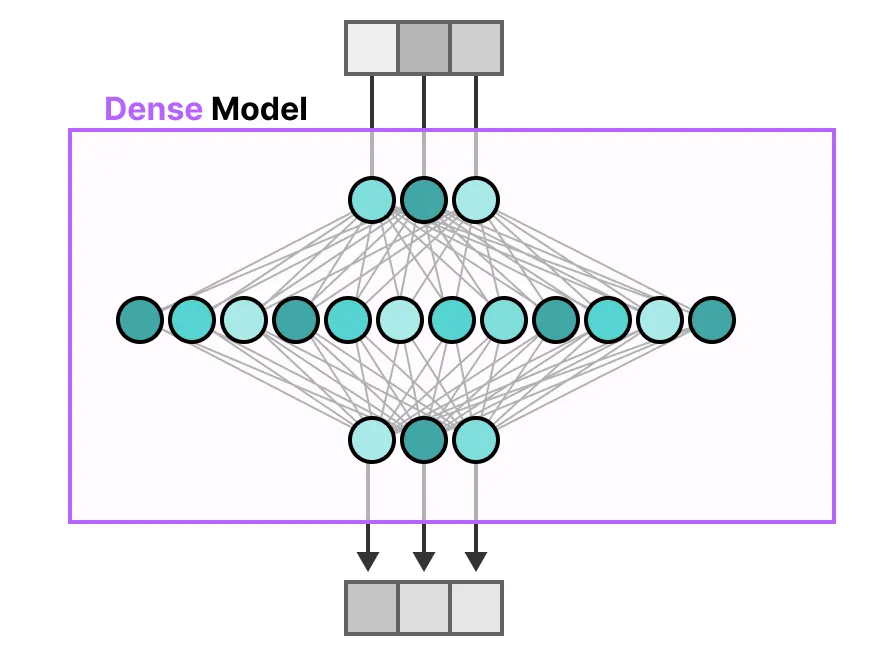
传统 Transformer 中的 FFNN 被称为密集模型,因为所有参数(其权重和偏差)都被激活。没有任何东西被遗漏,所有内容都被用于计算输出。
相比之下,稀疏模型仅激活其全部参数的一部分,并与专家混合(Mixture of Experts)密切相关。
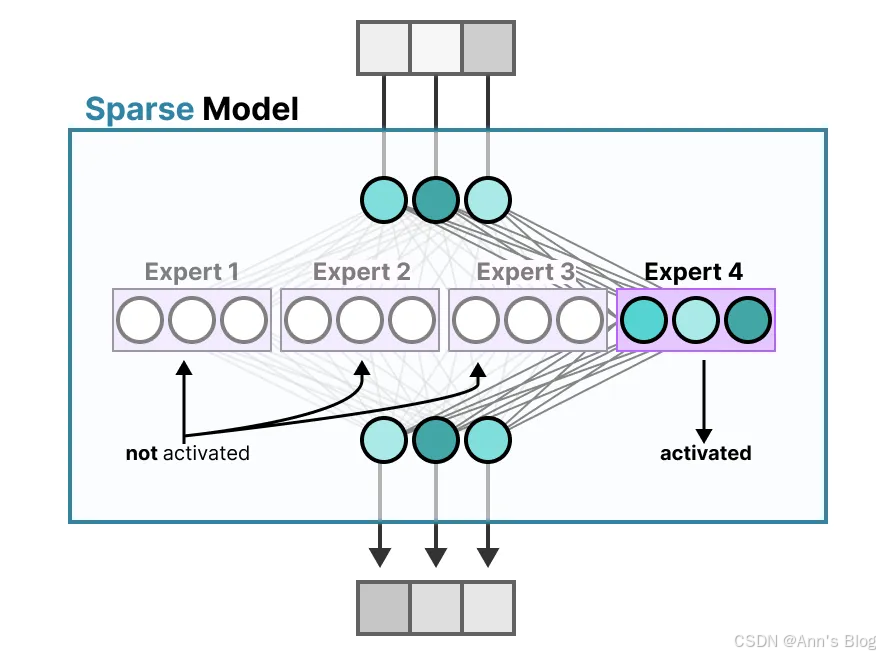
背后的思想是:每个专家在训练时学会了不同的知识。因此,在推理阶段也就是模型实际使用的时候
,只会调用那些与当前任务最相关的专家。
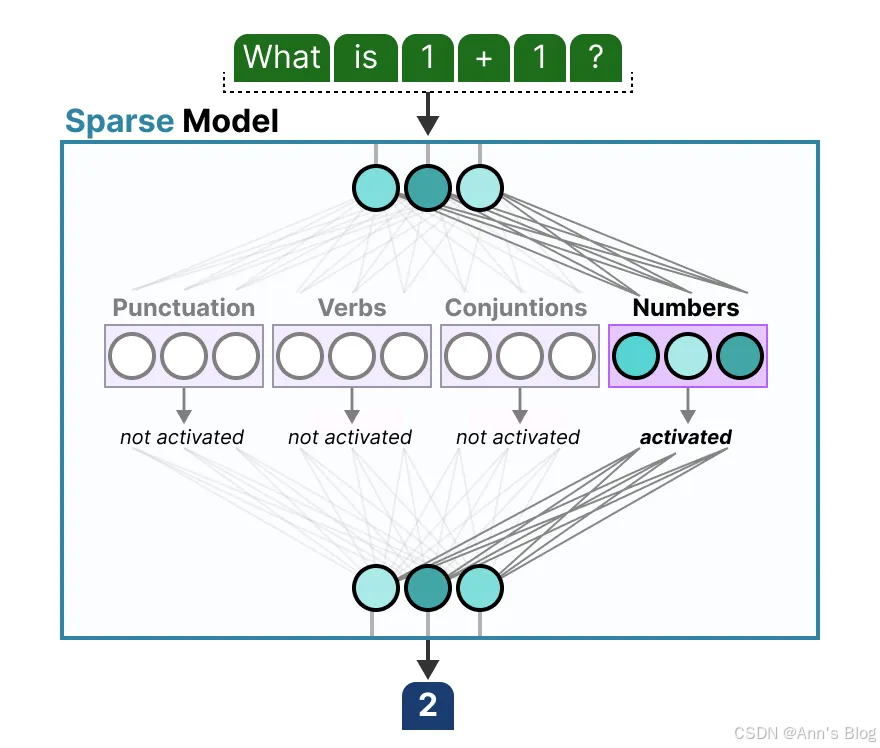
前边我们讲到了,专家所学的信息比起整个领域而言,是更为细粒度的信息。因此,有时称它们为“专家”其实有些误导人。
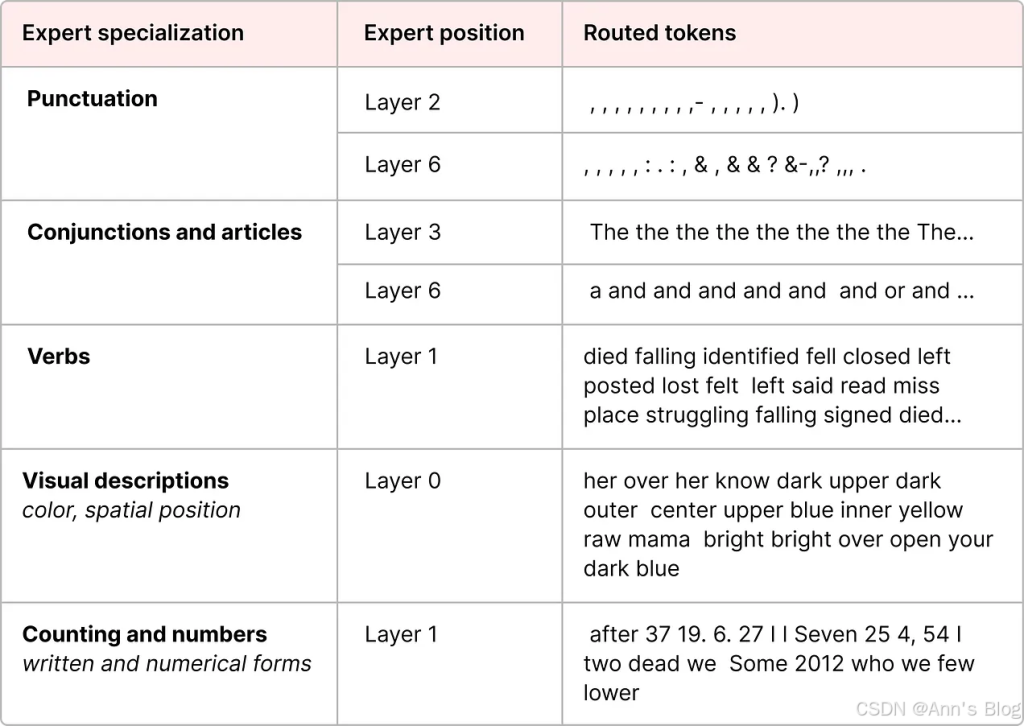
解码器模型中的专家似乎并没有相同类型的专门化。但这并不意味着所有专家都是平等的。
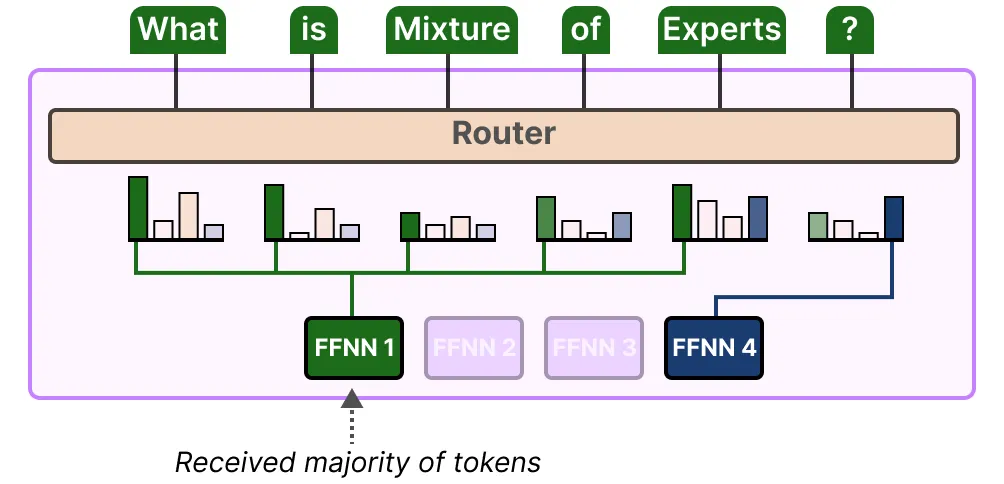
在 Mixtral 8x7B 论文中可以找到一个很好的例子,其中每个 token 都用首选专家的选择进行着色。

The Complexity of Routing 路由的复杂性
使用简单函数进行路由,在训练时会导致往往选同一个学得快的专家

不仅专家的选择会分布不均,而且有些专家几乎不会被训练。这导致在训练和推理过程中都会出现问题。
相反,我们希望在训练和推理过程中专家具有同等重要性,我们称之为负载均衡。从某种意义上说,这是为了防止对同一组专家过拟合。
为了平衡专家的重要性,我们需要关注路由器,因为它是决定在特定时间选择哪些专家的主要组件。
KeepTopK
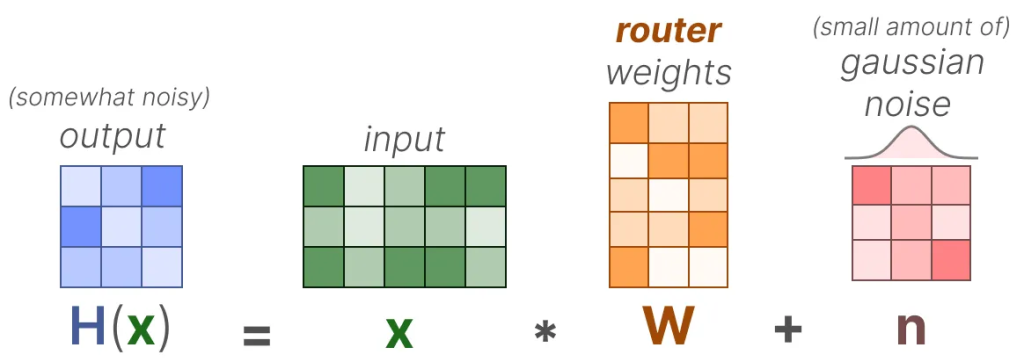
一种平衡负载的方法是通过一个简单的扩展,称为 KeepTopK(https://arxiv.org/pdf/1701.06538)。通过引入可训练(高斯)噪声,我们可以防止相同的专家总是被选中:
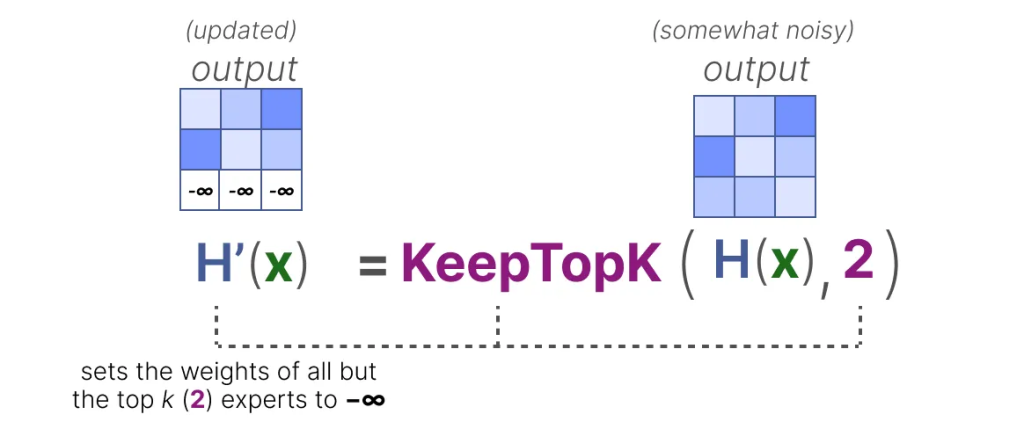
然后,除了你想激活的前 k 个专家(例如 2 个)之外,其他所有专家的权重将被设置为-∞:
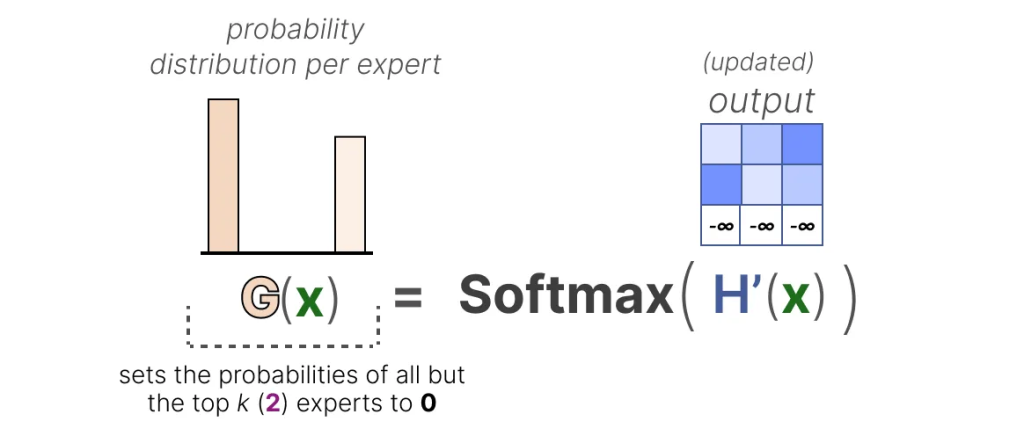
通过将这些权重设置为-∞,这些权重上的 SoftMax 输出的概率将为 0:
Token Choice Token 选择
KeepTopK 策略将每个 token 路由到几个选定的专家。这种方法称为 Token 选择 3,允许将给定的 token 发送到一个专家(top-1 路由)或者k个专家

Auxiliary Loss 辅助损失
To get a more even distribution of experts during training, the auxiliary loss (also called load balancing loss) was added to the network’s regular loss.
为了在训练过程中获得更均匀的专家分布,网络中添加了辅助损失(也称为负载均衡损失)到常规损失中。
It adds a constraint that forces experts to have equal importance.
它添加了一个约束,迫使专家具有同等重要性。
The first component of this auxiliary loss is to sum the router values for each expert over the entire batch:
这个辅助损失的第一部分是将每个专家在整个批次上的路由值相加:
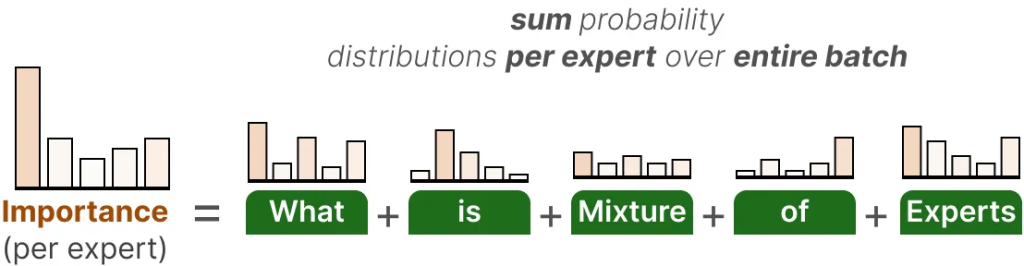
这给我们提供了每个专家的重要性分数,它表示无论输入如何,某个专家被选中的可能性。
我们可以用这个来计算变异系数(CV),它告诉我们专家之间重要性分数的差异程度。
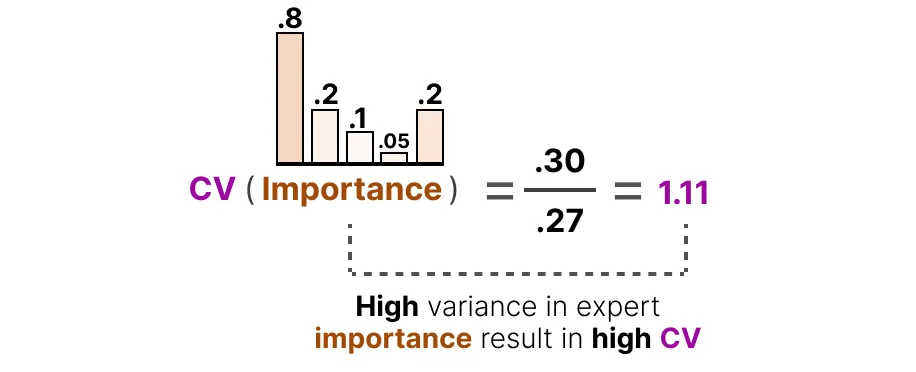
利用这个 CV 分数,我们可以在训练过程中更新辅助损失,使其旨在尽可能降低 CV 分数(从而给予每个专家同等的重要性):

Expert Capacity 专家容量
不平衡不仅存在于被选择的专家中,也存在于发送给专家的 token 的分布中。例如,如果输入标记不成比例地发送给一个专家而不是另一个专家,那么这也可能导致欠训练: