高可用的AI application系统设计
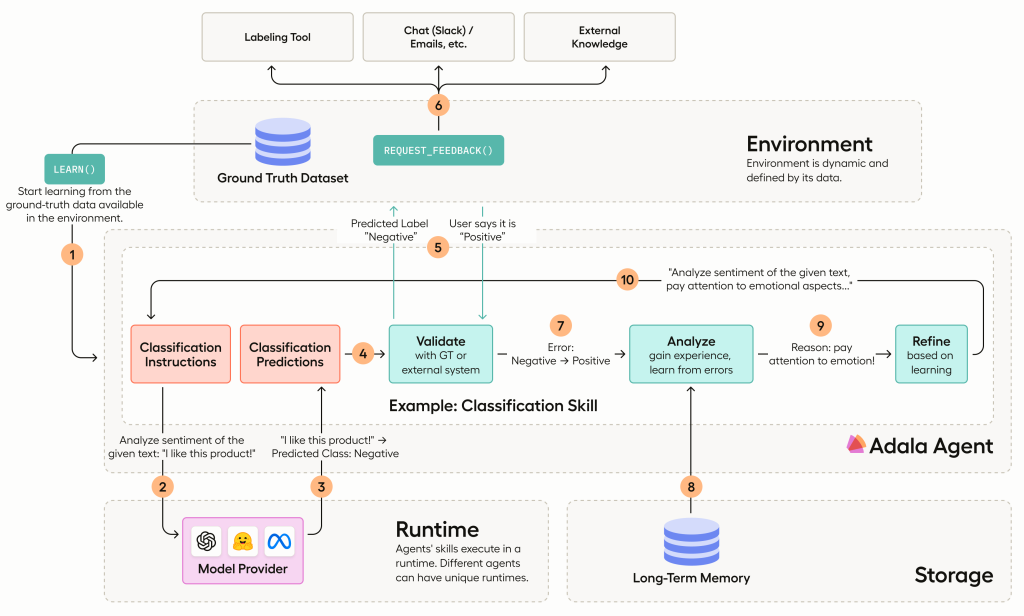
以上就是一个关于数据标注系统的AI application的系统架构,我们本篇文章主要围绕agent作为核心的框架进行探讨,更加偏向于基于api调用的模型核心构成的AI Application而非模型微调训练为核心的框架(这样能够动态微调训练的框架也很少)

上图是发布于2025.5.17的图片,于9.16进行新一轮处理时,变灰的是指基本上被抬出场的“玩家”,可以看到瞬息万变的AI+并没有给每个参与者那么充足的竞争机会,稍有不慎便跌落山谷。
因此要构建一个成熟的AI(agent)application框架,其中的每个组件都没有“必然性”,他都是可以替换、甚至可以熔断的组件(因为有些可靠性组件并非唯一且必须)
Developers often mistake tooling complexity for engineering sophistication.
不过一切应用的构建都需要注意这点,langchain原本作为AI infra重要的一环,曾经是很好用的脚手架,不过因为过多的调整原本已有的LLM 架构,并且过多进行封装和自定义,现在已经越发臃肿且使用困难,主要就是因为他的过度设计,导致很多地方变的比较不伦不类(很轮子但是缺骨架),不再是那个最好的工具箱了。
Contents
什么是AI framework
可能大家都不尽理解AI framework的含义,一般在当今语义中,AI framework可以指AI相关工具构建的一套完整的工具链,用于部署和运行,也可以指如上图所说的,以一个AI (agent)为中心搭建的一个framework。今天我主要讨论的应该就是后者,即围绕AI agent搭建的一套完整框架,以支撑AI agent的可靠使用
如何构建一个围绕大语言模型(LLM)的系统框架?
在真正着手设计和实现一套基于大语言模型(LLM)的系统框架之前,我们首先需要回答几个核心问题:
- LLM 究竟能做什么?
- 在使用 LLM 时,我们需要关注哪些关键因素?
- 传统软件架构中的哪些模块仍然适用于 AI Agent 框架?
- 又有哪些部分需要进行技术栈重构,甚至对原有工具链进行二次开发?
要回答这些问题,我们必须先厘清当前 AI 技术的能力边界。
当前 AI 能做什么?
随着 Transformer 架构的大规模高效训练取得突破,以 GPT 为代表的大型语言模型展现出前所未有的自然语言理解与生成能力。如今,LLM 已能胜任从简单问答到复杂推理、跨领域任务规划等多种场景。这股“大模型浪潮”催生了“AI 即将取代人类”的热议。然而,在实际应用中,我们也逐渐认识到其局限所在。
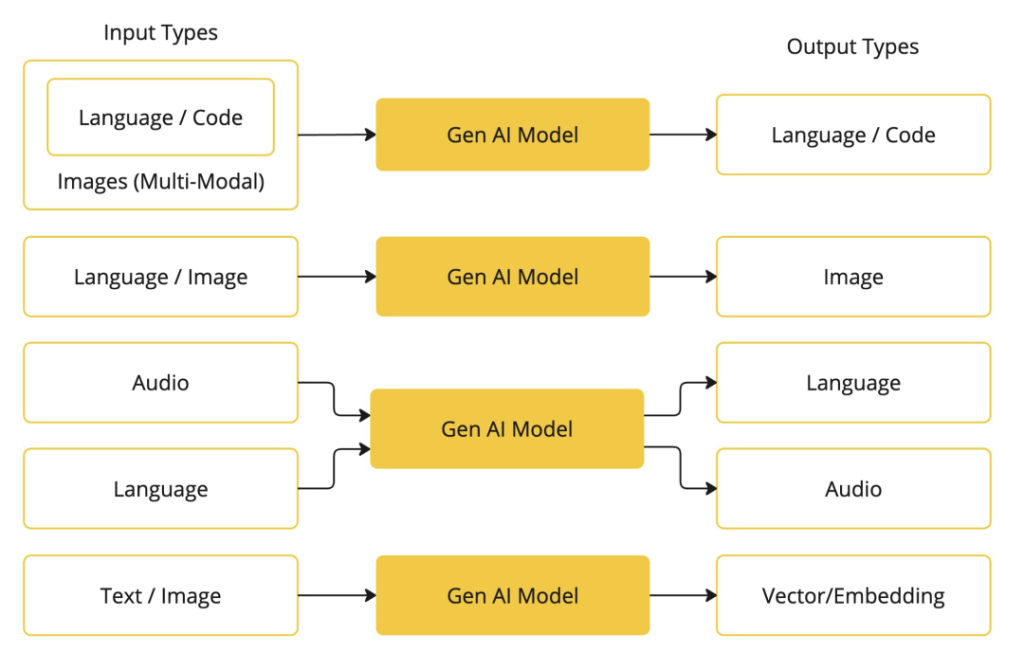
目前,LLM 及其衍生能力主要涵盖以下几个方向:
- 基础对话能力(Chat-based LLM)
这是 LLM 最原始也是最成熟的应用形式——通过自然语言交互完成信息传递、问题解答、内容创作等任务。对话作为人机交互最自然的方式之一,构成了几乎所有 AI 应用的基础入口。 - 检索增强生成(RAG, Retrieval-Augmented Generation)
结合向量数据库与语义搜索技术,RAG 允许模型在生成过程中引入外部知识,从而缓解幻觉问题并提升事实准确性。尽管商业化落地面临挑战(如数据更新延迟、召回质量不稳定),但在许多 AI Agent 和企业级知识助手系统中,它仍是不可或缺的一环。 - 代码生成(Code Generation)
LLM 在编程辅助方面表现突出,能够根据自然语言描述生成脚本、函数甚至小型项目骨架。虽然宣传中常被描绘为“全自动程序员”,但现实中其输出仍需人工审核与调整,尤其是在处理边界条件、性能优化和架构设计时。因此,现阶段更准确的定位是:强大的编码助手,而非完全替代开发者。 - 多模态内容生成(Multimodal Generation)
随着 CLIP、Flamingo、Qwen-VL 等模型的发展,LLM 正逐步融合图像、音频、视频等非文本输入/输出能力,支持图文生成、语音理解、视觉问答等任务。尽管已有显著进展,但在细粒度感知、跨模态一致性等方面仍存在明显短板。 - 工具调用与函数执行(Tool Use / Function Calling)
现代 LLM 支持结构化 API 调用,使其可以连接外部系统(如数据库、搜索引擎、自动化平台),实现“行动能力”。这是构建 AI Agent 的关键技术之一,让模型从“只说不做”转向“边想边做”。 - 模型上下文协议(MCP, Model Context Protocol)或其他状态管理机制
在复杂任务流中,如何维护会话状态、记忆历史决策、协调多个子任务成为关键。MCP 或类似的上下文管理协议正在探索中,用于标准化 agent 内部与外部环境之间的信息交换格式。
LLM 的优势与局限
综合来看,LLM 的强项在于:
✅ 能够理解和响应清晰指令;
✅ 在大众化、通用领域任务中表现出色;
✅ 支持自然语言驱动的灵活交互;
✅ 可作为“智能中枢”整合多种能力(检索、推理、工具调用等)。
但同时,也存在明显的缺陷:
❌ 对模糊或歧义 prompt 敏感,易产生偏差或错误输出;
❌ 在小众、专业或低资源领域缺乏足够训练数据,导致可靠性下降;
❌ 处理超长上下文时容易遗忘早期信息,注意力分布失衡;
❌ 多模态输入混合(文字+图像+语音)时,融合能力有限,易出现误解;
❌ 存在“幻觉”风险——生成看似合理但事实上错误的内容;
❌ 缺乏真正的因果推理与自我反思能力,难以独立完成高精度闭环任务。
这些限制意味着:LLM 不是一个万能解,而是一个强大的“协作者”。它的最佳角色不是完全自主地执行任务,而是作为智能代理(Agent)的核心引擎,在人类监督或系统约束下协同工作。
传统架构 vs AI Agent 架构:继承与变革
在构建 AI Agent 系统时,我们可以借鉴传统软件工程中的许多理念:
- 模块化设计:仍将系统拆分为感知、决策、执行、记忆等组件;
- 接口抽象:保持各模块间的松耦合,便于替换与扩展;
- 可观测性与日志追踪:对于调试和安全审计至关重要;
- 权限控制与安全性机制:防止滥用或越权操作。
但与此同时,也需要针对 AI 特性做出关键调整:
| 固定流程控制(if-else) | 动态任务规划(LLM 驱动) |
| 明确输入输出类型 | 自然语言为主,结构化辅助 |
| 数据驱动逻辑判断 | 模型驱动意图理解与生成 |
| 同步调用服务 | 异步、容错的工具调用链 |
| 静态配置 | 上下文感知的动态参数注入 |
此外,某些技术选型可能需要“二开”或深度定制,例如:
- 记忆系统需分层设计(短期记忆、长期记忆、经验回放)。
- 向量数据库需支持实时增量索引与元数据过滤;
- Prompt 工程需结合模板管理、A/B 测试与反馈闭环;
- 工具调用需定义统一 schema,并加入执行结果验证机制;